学一个新领域,我现在的第一步是把它抓下来
作者: 耳朵
最近一直在看 Simon Willison 的文章。
他是 Django 框架的联合创始人,现在是 AI 工具链领域最活跃的独立开发者之一,博客 simonwillison.net 上有超过十年的技术文章,内容覆盖 Python、SQLite、LLM 应用、数据工程……信息密度极高。
看着看着,我就想——能不能把他所有博客全部抓下来,做成一个私人知识库?以后想了解他对某个技术的看法,直接问 AI 就行,不用一篇一篇翻。
不光如此,这个思路可以推广到任何领域:找到某个方向最好的内容源,批量抓下来,做成你自己的领域知识库。
一:遇到的问题
我第一反应是直接告诉 OpenClaw 我的需求,让它帮我解决。
但是实测下来,单篇文章没问题,但批量抓取搞不定,它自己安装了一些开源工具做这事但是返回了很多无关的链接,所以它不具备直接做到「给我这个站点所有文章」的能力。
而我需要的是:
先拿到 Simon 博客上所有文章的 URL 列表。
再逐篇把内容抓下来,转成干净的 Markdown。
最好能直接在 AI 对话里完成,不用写代码。
后来发现了 XCrawl 这个工具,完美解决了这三个问题。
二:XCrawl 是什么
简单说,XCrawl 是一个网页抓取 API 服务,提供四个核心能力:
1. Search:搜索引擎查询,返回结构化结果(标题、URL、摘要、排名)
2. Map:扫描一个站点,列出它所有的 URL
3. Scrape:抓取指定 URL 的页面内容,输出干净的 Markdown
4. Crawl:全站递归爬取,适合大规模批量抓取
而且它提供了 OpenClaw 的 Skill,意味着你可以直接在 OpenClaw 里用自然语言调用这些能力,不用写任何代码。
使用时只需要先去 https://www.xcrawl.com/?keyword=ut0qflxk 注册拿到 Key,新账号有 1000 积分免费额度,然后把它的 Skill 文档链接 https://docs.xcrawl.com/zh/doc/developer-guides/openclaw/ 直接告诉 OpenClaw,然后龙虾就会自动安装相关的 Skill,我们的配置就完成了。
三:抓取 Simon Willison 的全部博客
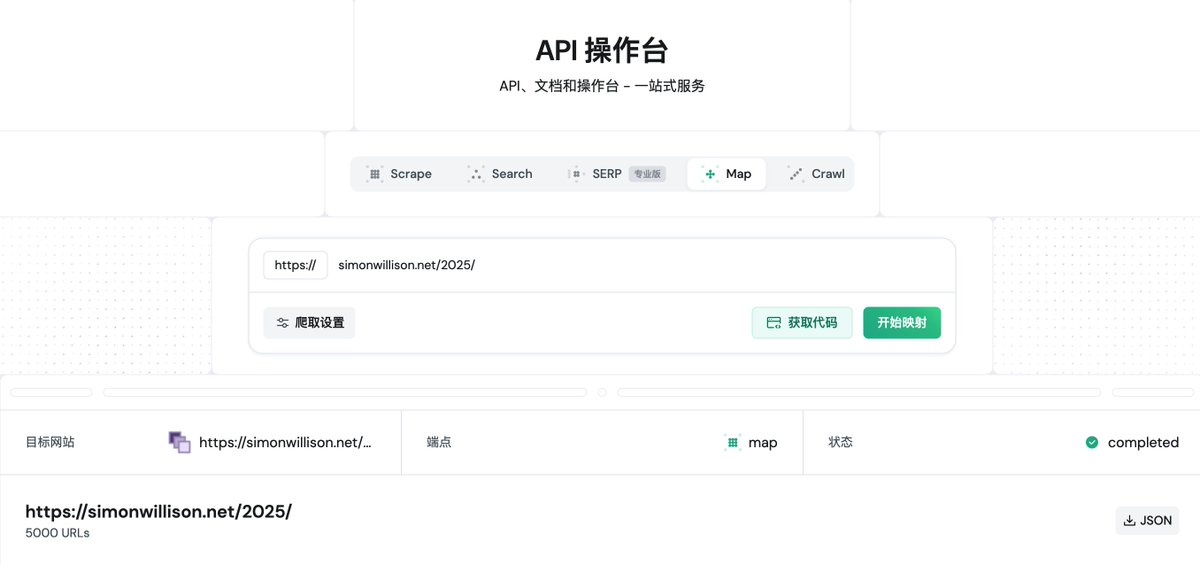
第一步,我先用 Map 功能拿到所有文章 URL:
Map 会扫描站点的 sitemap 和链接结构,返回所有符合条件的 URL,我按年份过滤,只要近三年的文章,实测拿到了 233 篇文章的 URL。
Simon Willison 真是高产,每年平均 100 篇文章,26 年才三月他已经写了 24 篇文章了。
接下来是第二步,我开始用 Scrape 逐篇抓取正文:
Scrape 是精确制导——一个 URL 对应一篇干净的 Markdown,不会抓到导航栏、评论区这些噪声。
233 篇文章,耗时不到十分钟跑完,每篇都是干净的 Markdown,标题层级、代码块、链接全部保留。
抓取的同时,因为输出就是 Markdown,我直接让 OpenClaw 把这些文件保存到本地文件夹。然后直接用 Claude Code 打开会话,让 AI 分析这些内容,现在我可以这样问:
说白了,我现在有了一个「Simon Willison 的大脑副本」,想学什么直接问。
四:从零构建一个陌生领域的知识库
上面的案例是「我已经知道要学谁」,但更多时候,你面对一个完全陌生的领域,连该看谁的东西都不知道。
这时候加一步 Search 就行:先搜关键词找到这个领域最好的内容源,再用 Map 摸清站点结构,最后用 Scrape 把符合你意图的文档全部抓下来。
比如我想系统学 WebAssembly,先用 Search 找方向:
Search 返回结构化的搜索结果——标题、URL、摘要、排名,我从 40 条结果里筛出 5 个高质量站点:核心文档站、深度博客、awesome 列表。
再用 Map 摸清每个站的结构:
对每个筛出来的站点跑一次 Map。有些站只有 20 篇文章,有些有 500 页但大部分是 API reference——Map 帮你在抓之前就做好判断,只选真正有价值的部分。
最后和上面的步骤一样,用 Scrape 定向抓取:
最终拿到 80 篇高质量文档,全部是干净 Markdown,直接存到本地做知识库。
从「我对 WebAssembly 一无所知」到「我有一个 80 篇核心文档的专属知识库」,不到两小时。
五:几点心得
Map 先行,永远是对的。不管你多确定要抓什么,先跑一次 Map 看看站点结构,很多站的 URL 规律和你想的不一样,Map 能帮你避免抓一堆垃圾页面。
Search 的语言设置很重要。同一个关键词,英文和中文的搜索结果差异巨大,技术领域建议优先搜英文,拿到的源质量普遍更高。
Markdown 输出是真的省事。因为输出直接就是 Markdown,我可以让 OpenClaw 直接保存到本地笔记库里,不需要任何格式转换,拿到就能用。
抓取稳定性比想象中好。XCrawl 底层会自动轮换 IP,批量抓几百篇文章速度也很快,隐私和安全性都很好,一些开源的方案会遇到一些禁止抓取的的情况,在这里没遇到过。
关于合规:XCrawl 内置 robots.txt 检测,只采集公开内容,但选目标站时还是建议手动确认一下抓取政策。
本质上我这套方法做的事情是:把互联网上散落的高质量内容,变成你的私人知识库,然后用 AI 帮你消化。
以前学一个新领域,你得自己找资料、自己读、自己整理笔记。
现在这个流程变成了:Search 找源 → Map 探路 → Scrape 抓取 → 存到本地 → AI 对话学习。
对我来说最大的变化是——学习的瓶颈从「找不到好内容」变成了「怎么问出好问题」。
这才是 AI 时代学习该有的样子。